Struts2 框架——阻止表单重复提交
本文共 204 字,大约阅读时间需要 1 分钟。
阻止表单重复提交
实现过程:
1.在from表单中,使用s标签会有一组UUID值;
<%@taglib uri="/struts-tags" prefix="s" %>

2.在struts.xml中配置拦截器,引入拦截类;
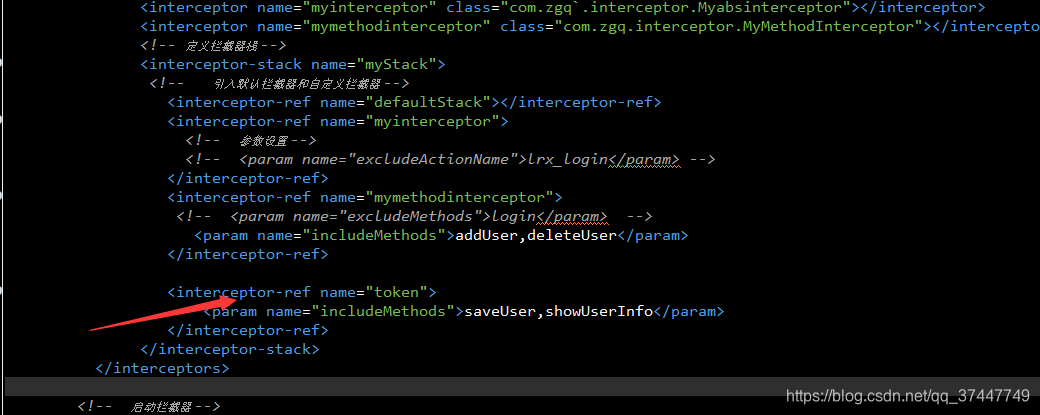
3.在jsp 页面引入struts标签,UUID存放页面的表单中;
阻止后跳转到》》》
<result name="invalid.token">/index.jsp</result>
转载地址:http://tdkcz.baihongyu.com/
你可能感兴趣的文章
MySQL 内核深度优化
查看>>
mysql 内连接、自然连接、外连接的区别
查看>>
mysql 写入慢优化
查看>>
mysql 分组统计SQL语句
查看>>
Mysql 分页
查看>>
Mysql 分页语句 Limit原理
查看>>
MySql 创建函数 Error Code : 1418
查看>>
MySQL 创建新用户及授予权限的完整流程
查看>>
mysql 创建表,不能包含关键字values 以及 表id自增问题
查看>>
mysql 删除日志文件详解
查看>>
mysql 判断表字段是否存在,然后修改
查看>>
MySQL 到底能不能放到 Docker 里跑?
查看>>
mysql 前缀索引 命令_11 | Mysql怎么给字符串字段加索引?
查看>>
MySQL 加锁处理分析
查看>>
mysql 协议的退出命令包及解析
查看>>
mysql 参数 innodb_flush_log_at_trx_commit
查看>>
mysql 取表中分组之后最新一条数据 分组最新数据 分组取最新数据 分组数据 获取每个分类的最新数据
查看>>
MySQL 命令和内置函数
查看>>
MySQL 和 PostgreSQL,我到底选择哪个?
查看>>
mysql 四种存储引擎
查看>>